EC2에서 이중화한 서버의 경우 시간대는 KST나 UTC로 맞추었지만, date를 찍어보면 2~3분 정도 시간차이가 발생하는걸 확인할 수 있다.
이런 경우 발생한 로그를 추적하기에도 어려움이 있기 때문에 시간을 동일하게 맞추어 주는 작업이 필요하다.
Amazon Time Sync Service를 사용하면 손쉽게 적용 가능하다.
아래와 같은 명령어를 입력하여 서버에 적용하면 서버간 시간대가 초 단위까지 일치하는 것을 확인할 수 있다.
$ sudo apt update
$ sudo apt install chrony
$ sudo vi /etc/chrony/chrony.conf
#server나 pool 문 앞에 아래 내용 추가
server 169.254.169.123 prefer iburst minpoll 4 maxpoll 4
#chrony 서비스 재시작
$ sudo /etc/init.d/chrony restart
#동기화 확인
$ chronyc sources -v
#동기화 지표 확인
$ chronyc tracking
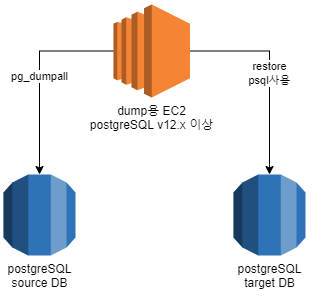
dump용 EC2 : postgreSQL client 버전 12 이상이 설치되어 있는 서버. source RDS와 target RDS에 접속가능해야 한다.
DUMP 수행
postgreSQL RDS는 rdsadmin 이 소유하고 있는 database가 있는데 이건 RDS 생성시 만들었던 master 계정이 권한이 없기 때문에 덤프를 뜨는게 불가능하다. postgreSQL 12버전 이상을 사용하면 특정 database를 제외하고 덤프를 뜰 수 있다.(–exclude-database 옵션)
덤프를 뜨기전, master 계정이 database에 권한을 가지고 있는지, tablespace 소유 여부를 확인한다.
# postgreSQL 접속
$ psql --host=(source RDS Endpoint) --port=(source RDS port) --username=(master 계정) --password
# db list 조회
> \l
# 사용자 권한 조회
> \du
# table space 조회
> \db
# master 계정 소유로 table space 변경
> ALTER TABLESPACE (tablespace 명) OWNER TO (master 계정);
# master 계정에게 db 권한 부여
> GRANT (db명) TO (master 계정);
master계정에게 권한이 부여되었다면, 아래 명령어로 rdsadmin이 소유한 database는 제외하고 dump를 뜬다. –no-role-passwords 옵션을 사용하여 super_user 권한이 없는 계정으로 dump를 뜬다. 복원 후 사용자 비밀번호는 다시 지정한다.
# target RDS 연결
$ psql --host=(target RDS Endpoint) --port=(target RDS port) --username=(master 계정) --password
# 사용자 정보 변경
> ALTER ROLE (사용자명) WITH LOGIN;
> ALTER USER (사용자명) WITH PASSWORD '(비밀번호)';
40 GB 데이터 베이스 기준으로 dump 뜨는데 30분, restore하는데 20분이 수행되었다.
pg_dump의 경우 table space 및 사용자의 권한은 복사되지 않고, 데이터 베이스 별로 덤프를 떠서 복원해야 하기 때문에 RDS 전체 데이터를 백업해야 하는 경우에는 pg_dumpall 이 더 빠르고 정확하고 편하다.
S3 서비스의 전체 이름은 Amazon Simple Storage Service이다. S가 세 개라서 S3로 부른다. 오브젝트 스토리지 서비스로 높은 내구성과 높은 가용성을 저렴한 가격으로 제공해주기 때문에 AWS 인프라를 사용하게 되면 로그 저장용이나 정적인 컨텐츠 보관용으로 꼭 사용하게 된다. S3의 내구성을 좀더 살펴보자면, S3가 제공하는 내구성은 99.999999999% 이다. 9개 무려 11개로 사실 이정도면 거의 서비스 다운이 없다고 보면 된다. (AWS의 모든 리전은 최소 3개의 AZ를 가지고 있는데 S3는 무조건 3개의 AZ를 전부 사용하고 있고, 물리적 복사본을 각 AZ당 2개 이상 가지고 있다.)
분산 구조라서 객체의 Create / Delete만 지원하고 Modify의 경우 overwrite(재생성)으로 진행된다. HTTP(S) 프로토콜을 사용하여 S3에 오브젝트 업로드/다운로드가 가능하다. 최종 일관성(Eventual Consistency)를 지원하기 때문에 Overwrite나 Delete의 경우 내부 복제가 완료되기까지 약간의 시간이 걸릴 수 있다.
버킷(Bucket)과 객체(Object)
S3 서비스에서 객체(Object)를 저장하기 위해서는 Bucket 이라는 걸 만들어야 한다. Bucket은 객체를 담는 바구니, 우리에게 익숙한 개념으로는 폴더라고 생각하면 된다. 다만 버킷은 Flat한 구조라서 버킷 내부적으로 하위구조(Hierachie)를 가질 수는 없지만, “/”를 구분자로 하여 논리적으로 하위구조를 가질 수 있게 해준다.(folder/object와 같은 형태)
버킷은 기본값이 private이다. public으로 열고 싶으면 S3 버킷 정책에 대해 살펴보아야 하는데 보안상 public으로 여는건 권고하지 않고 있다. 버킷명은 모든 AWS 계정, 모든 region에 걸쳐 전세계적으로 고유한 값이다. 버킷주소는 “버킷명.리전명.amazonaws.com”의 형태이다.
객체는 버킷에 저장되는 오브젝트로 최소 1Byte에서 최대 5TB까지 가능하다. 저장 가능한 객체의 갯수는 무제한이다. 역시 기본값은 private이고 객체의 주소는 고유한 형태로 버킷명+키값(오브젝트명)이다.
S3 접근 권한 없는 사용자가 private S3에 접근하기(pre-signed url 발행)
S3 버킷의 기본 정책은 private이다. public에서 접근해서 object를 다운받거나 업로드 해야 하는 경우 버킷 자체를 public으로 열기엔 부담스럽고, 그렇다고 pulblic에 있는 사용자에게 S3 접근권한을 일일히 부여하기도 번거롭다. 이럴 때 사용할 수 있는게 pre-signed url이다. S3 접근을 위한 임시 url로 일정 시간이 지나면 만료되어 public 접근이 불가능해진다.
1. S3 접근 권한이 없는 사용자가 S3 접근 권한을 가지고 있는 EC2에 HTTP(S)등의 API로 S3 접근 권한 URL을 요청한다.
2. EC2에서 S3로 pre-signed url 발행을 요청한다.
3. S3에서 pre-singed url 을 발행하여 EC2에 전달한다.
4. EC2는 url을 사용자에게 전달한다.
5. 사용자는 발행받은 url (pre-signed url)로 S3에 접근하여 업로드/다운로드를 수행한다.
실제로 어떻게 구현되는지 하나씩 살펴보겠다.
먼저 EC2에서 AWS Credential을 가지고 오는 부분은 전에 작성한 페이지로 대체한다. 요약하자면 EC2는 Role로 S3 접근권한을 가질 수 있다.